
Time for another Friday Feature! Oddly, it feels like these weeks are slowly getting shorter and shorter. But I doth protest too much, because today I got a spot of great news that is entirely off scope ![]() . Also, I’m happy to say that WordPress 3.6 has finally been released and the website is no longer running on the beta. I see they have fixed the great bane that has been mine, of the post editor frequently losing “connection” to the server and disabling saving. Thank goodness! Anyways, let’s get on with it!
. Also, I’m happy to say that WordPress 3.6 has finally been released and the website is no longer running on the beta. I see they have fixed the great bane that has been mine, of the post editor frequently losing “connection” to the server and disabling saving. Thank goodness! Anyways, let’s get on with it!
So one of the things that made XNA very popular and easy to use was its content pipeline. Not only was it well designed and easy to extend, it also dramatically cut down on project startup time. You could jump right into the development of your application without worrying too much how to load models, textures, fonts, and so forth. Content management is a fundamental problem everyone has and it’s a hard one to solve. Sometimes it is also a boring one too.
Perhaps my only criticism of the XNA content pipeline was it was mainly geared for off-line content processing and could be difficult to do run-time content processing, since the end user required the Game Studio to be installed due to licensing issues.
Everyone Has Cool Graphics
So the reason why I mention XNA’s content pipeline is that many homebrew graphic engines tend to only focus on the super cool rendering effects. These features can certainly accumulate into an awesome tech demo. But let’s face it, everyone has cool graphics these days! The graphics capabilities of my engine, other hobbyist engines is no different than someone hacking something together with plain old SharpDX. Under the hood, we’re all submitting the same drawing commands. Most of the work for these cool rendering features lie in shader work.
Thus, I tend to be wary of such open source projects (like my own!), because the output may have be cool and advanced looking, but the code may never have really been designed for anything but the demo. As I have said before, I am no fan of a framework that does everything for you, because they tend to turn into millstones your neck as a developer if you stray off the beaten path. In addition, these projects are often devoid of a coherent content pipeline, or offer only a few narrow workflows of loading models/textures. Generally there is no unified content pipeline or there is something, but it’s not at the level of sophistication as XNA’s.
So philosophically, that is one thing I have striven with Tesla’s development (past and present), to focus on the not-so-pretty features that are just as crucial as the sexy graphics. I hope that Tesla’s content pipeline sets the engine apart from other solutions out there.
I have a very good example actually. One of the more beautiful and cool rendering demos I have done while working on the (old) engine, was that planetary shader effect. People still talk about it. It is very cool looking afterall. However, 99% of the work that went into that demo went into the shaders, not the application code. It would have been just as easy putting it together using SharpDX. So the rendering alone was not useful in answering the question “why use my engine?”.
I’ll tell you why. My favorite part of that planetary shader demo wasn’t the cool effect, but the Material Scripting that I used for it. It’s part of the download if you care to take a look. That was more awesome to me, because it showed an easy way to tweak your rendering without hard coding values. It also showed how you could easily hook up shader parameters (such as World-View-Projection and Camera positions) to be automatically fed to your shader without requiring custom application logic. That is one of the reasons why the application code for the demo was extremely small. It also means that I can make changes on the fly without recompilations or have a more artist-driven workflow.
The ramifications of those points are rather huge, and it’s all content pipeline related.
The Tesla Content Pipeline in a Nutshell
The engine’s content pipeline is split into two groupings – import and export. The engine handles two types of content – raw and compiled. Raw content are resources that need to be processed in some manner, like loading a JPG image and generating mip maps. Or loading a model from some file format and processing it into an internal mesh format. Compiled content are resources that have already gone through this processing step, and subsequently exported. Loading these resources back up is a simply manner deserialization the stream data into the runtime object.
Importing content has three major phases:
- Resource location and access through an IResourceRepository. Previously these were locators, now they’re abstractions of a file system, whether it be the disk, archive, or other. Or to access Storage Files in a Windows Store app.
- Processing the resource through a resource importer and creating the runtime object. Raw content may be post-processed in some manner in this step. Importers are tied to file extension types.
- Management of the loaded runtime object, in a ContentManager such as caching and disposing. Generally this manager handles querying and loading resources and manage importers.
These phases are outlined in the following diagram:
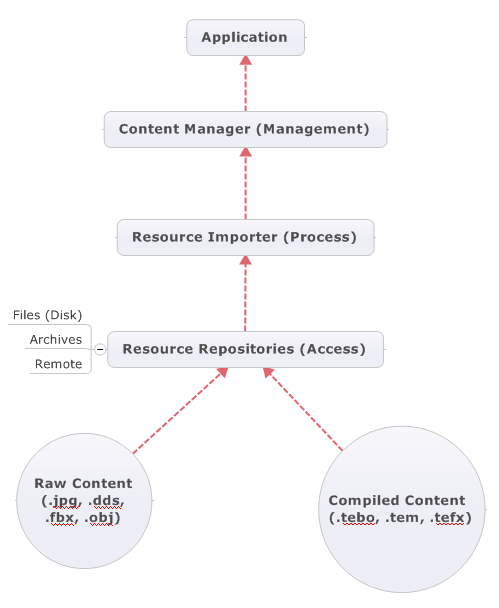
I won’t get too much into each step, as they should be fairly self-evident. If you’re familiar with the XNA content pipeline, you will note that the resource importers/exporters serve as a dual role of both importer and processor. Likewise, a content manager can have a number of registered importers to it, which allows for runtime processing of raw content. By default, content managers can only import the compiled content types, since those are meant to be formats that are available on every platform the engine is available on.
Exporting content is very similar, with the following two major phases:
- Using a resource repository to create a stream to a resource file.
- Processing of a resource through an exporter to that stream.
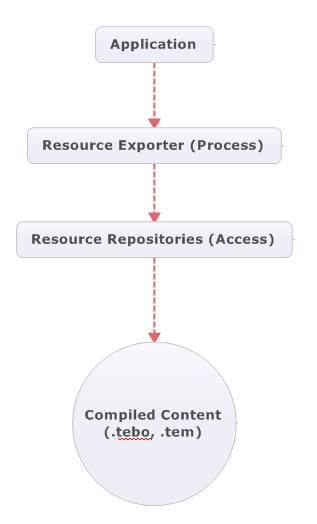
Types of Compiled Content
So from the diagrams, I mention three file formats as compiled content. They are acronyms:
- Tesla Engine Binary Object (TEBO)
- Tesla Engine Material (TEM)
- Tesla Engine Effect (TEFX)
Obviously, there is a distinct naming pattern there. The first format is the defacto format for all engine serialization, it is analogous to XNA’s XNB container. It is the fastest and most compact and is intended to be able to be loaded on any platform that the engine can run on. At the heart of it, is the ISavable interface which I will get into in a moment.
The material scripting format is a simple text file which is unique to the graphics system (reading and writing of material objects). The last format is relatively new, it has little to do with serialization – instead it’s a pure data dump of compiled shader byte code and reflected metadata (with some header information). It’s the output of the engine’s effect compiler, which is a standalone component. So usually that data is embedded in other containers, such as TEBO files. It’s a pseudo compiled file, since there is no runtime processing when it is loaded, but at the same time it doesn’t represent a “savable” object either.
Savable Serialization
A “Savable” is an object that can be saved to a stream, and loaded from another stream, where the object is in complete control of both processes. The interface looks like this:
public interface ISavable {
void Read(ISavableReader input);
void Write(ISavableWriter output);
}
The name is actually a throwback to a similar mechanism in an old java engine I used to use way back in the day. A TEBO file is a binary representation of a savable object. However, it is not the only representation. The serialization mechanism is not actually tied to a specific format as it is completely interface based. It is merely an abstracted way to do really fast serialization/deserialization with using minimal reflection. That is why objects are in control of what to read and write, as well as any versioning.
At some point we will have an XML file format, although that is a low priority right now. The binary representation is the more practical (and compact) representation that is the “universal” container for all platforms. Just like XNA’s XNB format, anything in the engine can be serialized to this representation for later use. The data that is written during serialization is actually given a name, which for the binary file is simply dropped. But the idea was to be able to support non-binary formats like XML, where the data could just as easily be human readable as well.
The interesting bit with savable serialization is that the interfaces support the concept of Shared and External references. Some savable resource, whether it is from a binary representation (TEBO) or XML, is in fact a single root object of type ISavable. That object may actually just be a collection, or may be some object with many dependencies on other savables. However, the savable resource also maintains a list of shared savable instances.
A common example would be a render state, or a vertex buffer – these objects may be defined once, and the same instance is used in multiple places. During serialization, the shared instance must be declared as such, and every time the same instance is encountered, an index to the shared list is written, rather than the instance’s data. The benefit should be self-evident,
Meanwhile, external references, are other savable resources that are located relatively to the primary savable resource that is being written to or read from. Examples of this may be a material script or a texture. A texture may be shared between many different and unrelated meshes. It would be unnecessarily costly to embed the texture data directly into all of the resource files that contain each mesh, having them separate means that texture file is available to other processes. This also has the benefit of allowing the content manager to only load one instance of that texture, to be shared by all at runtime.
So the benefits of these two concepts are to reduce data replication, both at runtime, as well as on disk. While all the dependencies of a single savable object can be neatly serialized into the same primary resource file, they don’t have to be. It’s a very configurable serialization mechanism.
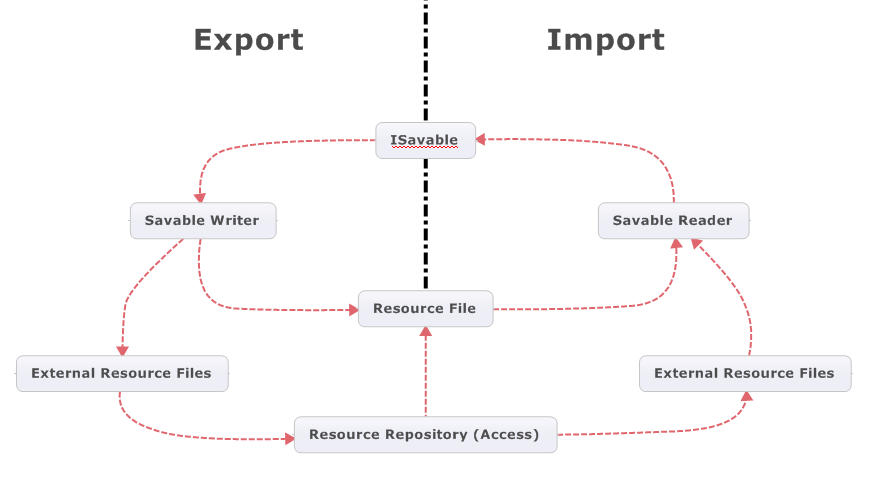
Also worthy of mention, is that the binary representation is capable of packaging savable data in a compressed byte stream.
Another aspect to the serialization scheme is the addition of a new concept: Primitive Values. These can be thought of a “light weight” version of a savable, intended for structs rather than full-fledged objects. They implement the IPrimitiveValue interface:
public interface IPrimitiveValue {
void Read(IPrimitiveReader input);
void Write(IPrimitiveWriter output);
}
This idea was born out of the type explosion in the engine’s Math library (lots and lots of new types!). The old reader/writer interfaces all had specific methods for writing and reading the different math types. Clearly, I needed a more flexible solution. The old ISavableReader and ISavableWriter interfaces are now split into two – IPrimitiveReader and IPrimitiveWriter handle all the .NET primitives (short, int, double, etc) as well as:
- Enums – ReadEnum<T>() and WriteEnum<T>()
- Primitive Values – Read<T>() and Write<T>() (and array variants)
- Nullable Primitive Values – ReadNullable<T>() and WriteNullable<T>()
The savable reader/writer interfaces are a lot smaller as a result, as they only handle the ISavable interface. Nearly every structure in the engine implements the IPrimitiveValue interface, so quite a bit can be serialized!
Likewise, ISavable is implemented in many areas of the engine. All the data buffers can be serialized, as well as relevant graphic resources such as buffers, textures, render states, and effects. Each of these object types are completely self-describing, and all serialize to a formalized object container. The engine has a truly unified means of reading and writing content, one that is extendable to allow for new format types, and easily allow developers to plug into the system to serialize their own content without modification. As well as be able to define new importers to be able to load new types of content, all within the same common importer paradigm. It all just works ™. Pretty awesome stuff if I say so myself.
And its features like that, which floats my boat. I love cool graphics, but I also love stuff like this.
Leave a Reply